BERT研究进展—从传统架构到ModernBERT的演进(截至2025年初)
作为一名前ChatGPT时代的NLP算法工程师,可以毫不夸张的说,我的职业生涯都是靠BERT活下来的。在面对标注数据稀缺的场景,它的性能足够好,训练足够简单,结果足够可控,改起来也足够简单。ChatGPT出现之后,以GPT架构为基础的各种大模型层出不穷,BERT的声音似乎越来越小了。不过,ModernBERT的出现,让我又看到了世界上还是有那么一群人,依旧在发掘它的潜力和价值。
这篇文章主要记录ModernBERT和ModerBERT-Large-Instruct两个模型的研究成果,由于这两个模型对应的论文和博客内容已经非常详尽,我这里只会摘出比较重要的一些结论和我觉得存在的问题。
ModerBERT
官方博客文章:
Finally, a Replacement for BERT: Introducing ModernBERT – Answer.AI
介绍视频(油管链接):
ModernBert: time for a new BERT
模型链接:
中文模型链接:neavo/modern_bert_multilingual (注:该模型的作者正在开发ACG内容自动翻译工具,使用ModernBERT模型进行NER任务)
要点总结:
- 高性能,低资源消耗
- 支持8k上下文长度
- 模型预训练过程中,混合了代码数据
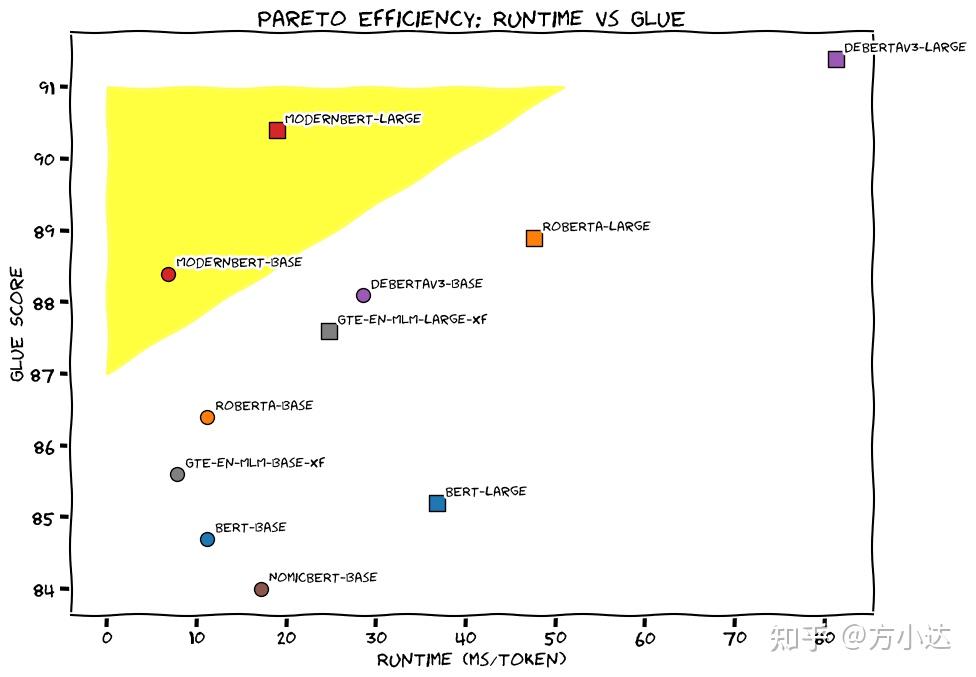
不足之处:
- 中文支持(尚未有组织或者机构进行ModernBERT的训练)
- 论文中只描述了输出处理过程,没有任何实际处理代码或者处理后的数据释出,无法复现
ModerBERT-Large-Instruct
介绍的博客文章:TIL: Masked Language Models Are Surprisingly Capable Zero-Shot Learners
模型链接:answerdotai/ModernBERT-Large-Instruct
中文模型链接:暂无
要点总结:
- 直接使用[MASK]做分类任务的目标,抛弃了传统的[CLS]头,模型性能得到了一定的提升
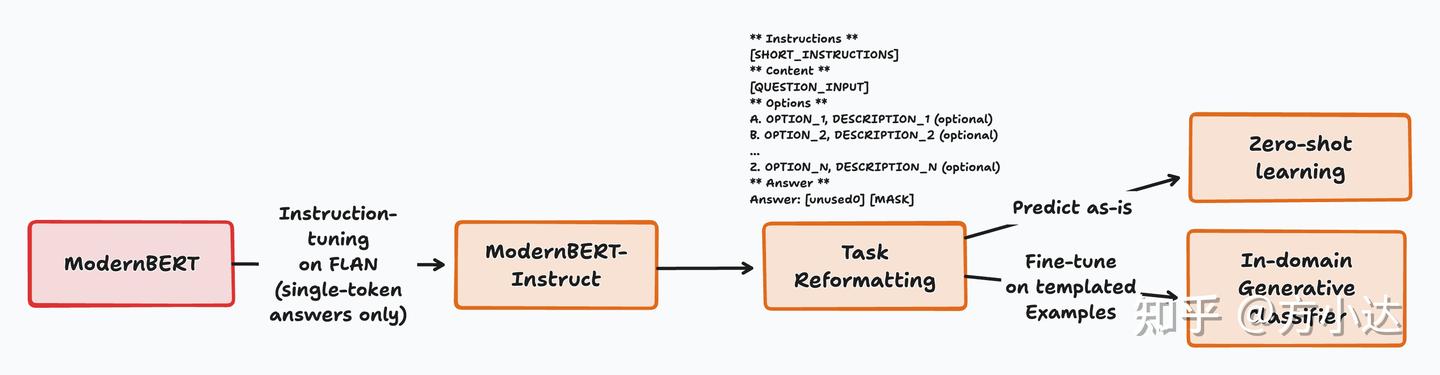
2. Zero-Shot 能力出色(使用的测试集为MMLU-Pro),相当于3~4倍参数量的GPT架构的模型(从这里可以看到Qwen模型是真的强)
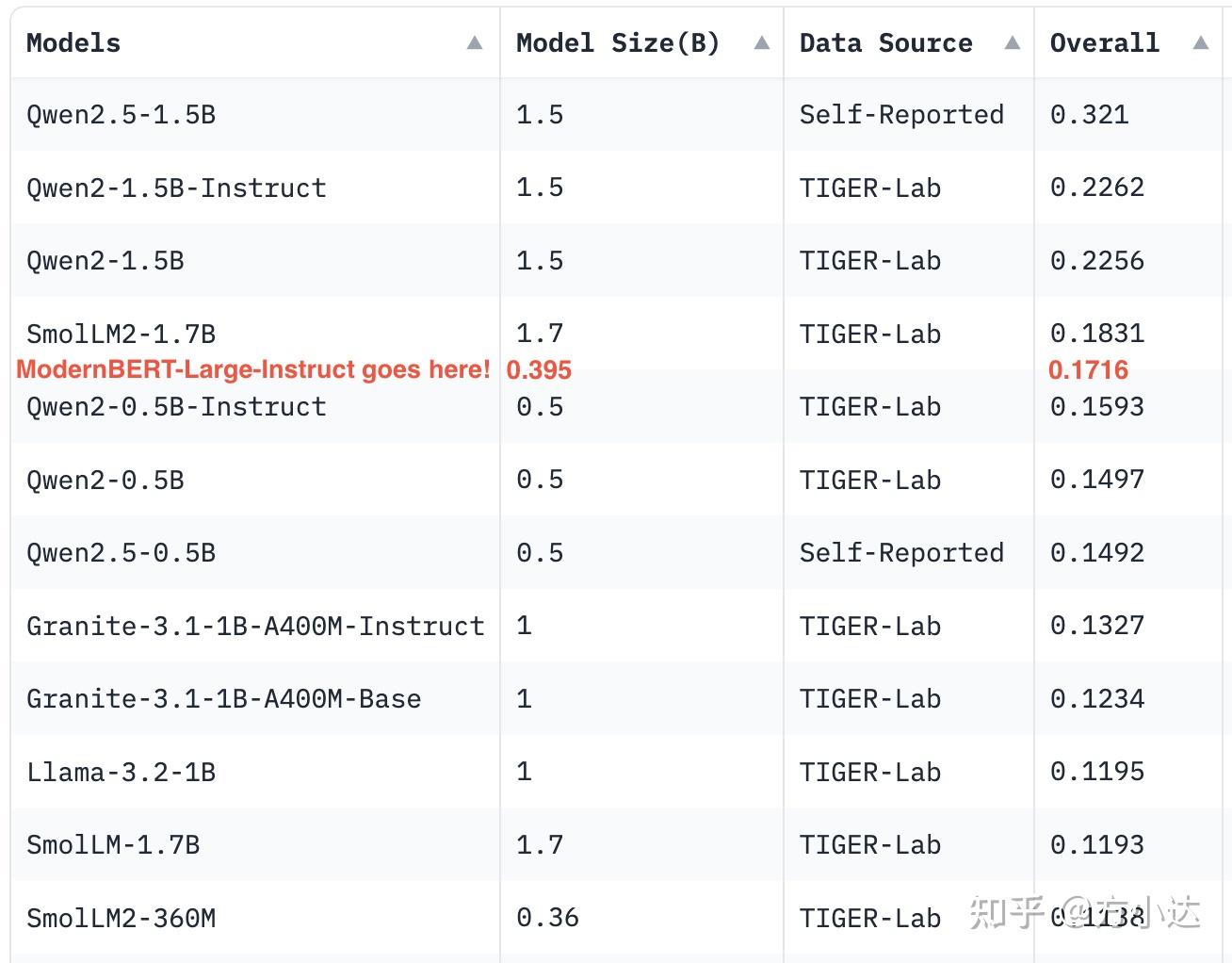
针对20亿以下模型的MMLU-Pro排行榜
3. 进行微调后,准确率和普通的CLS方案基本一致,在更细粒度的分类上有一些优势
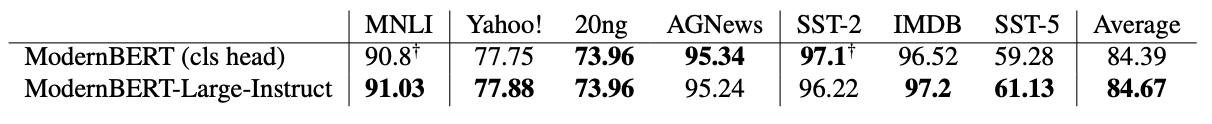
4. 模型预训练的过程中,使用了80%的真[MASK]和20%的假[MASK]的混合,假的[MASK]标签就是对应的目标就是一个[MASK]标签,这种方法让模型的能力得到了提升,作者认为这个相当于起到了一个正则化的效果。
5. 还有许多可以探索的空间:
- 探索更好的、更具多样性的模板生成
- 对训练机制进行更深入的分析,以及虚拟示例的效果
- 在更近期的指令数据集中进行测试,具有更好的构建质量
- 调查少样本学习能力
- 扩展到更大的模型规模
不足之处:
- 巨大的提升主要针对于Zero-Shot场景,在实际的应用中可能意义不大
- 没有中文支持
以上就是最近的两篇BERT相关的论文的汇总,希望我的文章能够让更多人认识到BERT模型的潜力,在低资源高性价比的方案中,更多的尝试使用BERT来解决问题。
如果你觉得这篇文章对你有所帮助,欢迎赞赏~
感谢您的支持

微信支付

支付宝